Key New Features in 1.0
Fundamental features like schema evolution and time travel have been present in the DuckLake spec since launch. The latest release adds even more capabilities.
We have borrowed extensively from the DuckLake 1.0 blog from the DuckDB Labs team for the code examples below!
Stable Specification
Data lakehouses last a long time. DuckLake 1.0 brings stability to the specification and backwards compatibility moving forward. As an open specification with open storage formats, you can move your data in or out of DuckLake at any time.
The foundational architecture of DuckLake is already rock solid: DuckLake is a novel integration of tried and true technology! Parquet files on object storage are industry standard. SQL databases like DuckDB and Postgres are very mature as well.
Taken together, DuckLake 1.0 is a much easier choice than when it was in beta!
Multi-Engine Support
Your lakehouse should be your single source of truth, with the ability to use multiple engines according to the workload. Query DuckLake with DuckDB locally, in the cloud with MotherDuck, using Apache DataFusion, or with a distributed system like Trino or Spark (if you need it).
That's the power of a stable and open specification - version 1.0 makes it even easier for additional engines to support DuckLake.
Data Inlining
This unique feature of DuckLake receives a significant upgrade in version 1.0. Data inlining is designed to solve the "small file problem" that can happen if data is frequently added to existing lakehouses.
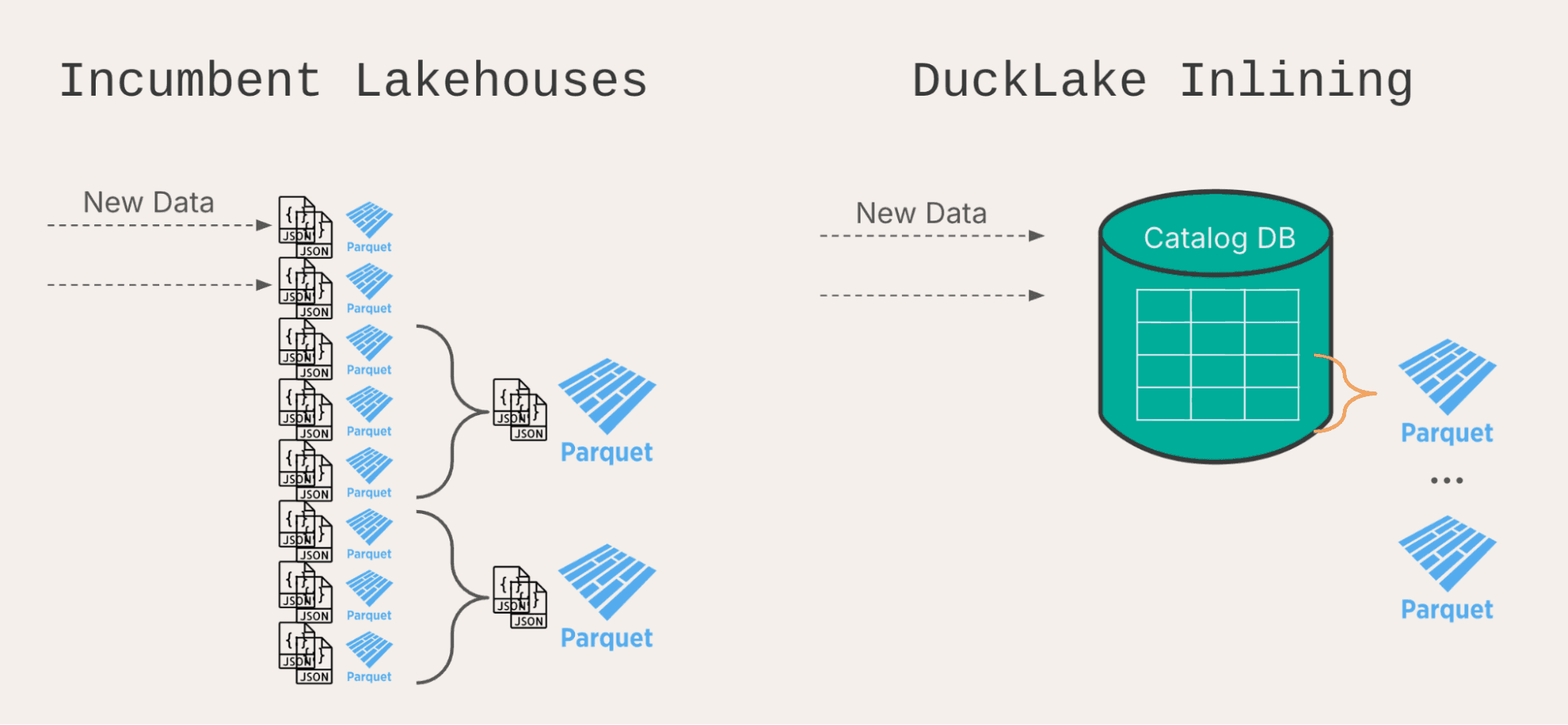
Iceberg and Delta will create multiple files for each insert, no matter how small. Adding a few rows still requires creating a separate set of metadata files and Parquet files. This makes small insertions very slow on a per-row basis, and after a short while, the high volume of metadata files slows down read queries also. Every query needs to check thousands of files.
Practically, this limits how often data can be added to a traditional lakehouse. However, slowing down source systems is not usually possible, so instead, data platforms need to add buffers using streaming systems like Apache Kafka and Apache Flink. This can add a lot of complexity. Frequent compaction can be necessary as well, which can require substantial compute too.
With DuckLake's data inlining, small inserts can be sent to the catalog database instead of creating separate files. Separate rows in a low-latency database are much more efficient than separate files on high-latency object storage! Once enough rows have accumulated, the inlined catalog database can be flushed out to appropriately large Parquet files.
Data Inlining solves the small files problem before it even occurs!
In version 1.0, data inlining can be used not only for inserts, but also for updates and deletes as well. This expands the number of use cases where it can apply. Any small modification is eligible! It is common to perform a deduplication step during ingestion using a merge, so updates frequently come in handy for data pipelines.
Inlining is enabled by default on all new tables in DuckLake 1.0 and can be adjusted like this:
ALTER TABLE my_lakehouse.my_table
SET (data_inlining_row_limit = 100);
When enough rows have accumulated, flush to Parquet with:
CALL ducklake_flush_inlined_data(
'my_lakehouse',
table_name => 'my_table'
);
Data Clustering
When running selective queries, like reading data from a certain category or within a specific set of customers, it is important to be able to read only the data that meets the filter criteria. In database lingo, this is called predicate pushdown (a predicate is a set of filters from a where clause). DuckLake does this in 2 levels: at the file level, and then within the Parquet file (at the rowgroup level).
To filter well at the file level, choosing a good partitioning strategy will allow DuckLake to only read from partitions with data that matches the where clause. DuckLake also uses file-level statistics to perform "hidden partitioning", so you don't need to have the exact partition column in your where clause.
Data clustering allows the second level of filtering to work more efficiently. It does this by sorting data within each file when inserting, compacting, or flushing inlined data. If data is sorted on the same column or expression that queries filter on, queries can read a small fraction of each file instead of all rows.
When sorting and query patterns are aligned, this can enable 10x faster read queries!
I am a big fan of this feature, but I'm exceedingly biased - this was my first contribution to DuckLake! -Alex
Enable sorting with this command:
ALTER TABLE my_lakehouse.events
SET SORTED BY (event_type DESC);
If you only want to sort "behind the scenes" during compaction or inline flush to keep insertions lightweight, disable sorting on insert:
CALL my_ducklake.set_option(
'sort_on_insert', false,
table_name => 'events'
);
Bucket Partitioning
Partitioning is an excellent strategy for segmenting data into smaller categories, but there is a practical limit to how many partitions are helpful. Many tiny partitions could trigger the small files problem (slowing read queries significantly) if any query were to need to access multiple partitions.
As a middle ground, bucket partitioning can create a fixed number of buckets and then use a hash to assign individual values into those buckets.
For example, for a dataset with 1 million customer ids, bucketing into only 1000 partitions could be a good balance between selective queries on a single customer and ones that read the entire dataset. Implement that in DuckLake with this SQL:
ALTER TABLE my_lakehouse.events
SET PARTITIONED BY (bucket(1000, customer_id));
Geometry Types
Now that the GEOMETRY data type is in DuckDB core, DuckLake is able to support faster read queries on geospatial data by using more advanced predicate pushdown. Geospatial filters like "show me all the places that overlap this polygon region" can run substantially faster by filtering out files that are guaranteed not to overlap using file level statistics.
Variant Types
 This duck can shred JSON.
This duck can shred JSON.
Think of the VARIANT type like a supercharged JSON data type. It stores data in a binary format instead of a string, and it is possible to automatically split a single logical variant column into multiple physical columns. This process is called shredding.
Shredding can make some operations significantly faster, like filtering down to keys with a specific value. There are many use cases for selective filtering when working with JSON data, like logs or observability metrics.
CREATE TABLE my_lakehouse.events (id INT, payload VARIANT);
INSERT INTO my_lakehouse.events VALUES
(1, {'user': 'alice', 'ts': TIMESTAMP '2024-01-01'});
SELECT *
FROM my_lakehouse.events
WHERE payload.user = 'alice';